I’ve been researching SDN, interviewing routing geeks, going to presentations and the one thing they all have in common is the blah blah. Like a bunch of music majors (FYI – I’m a music major) turned SDN marketing geeks that can’t find a job and heard about SDN and now they have learned to use big words like ‘ecosystem’, ‘hypervisor’, ‘virtualize’, ‘east-west’, ‘tenant’, ‘orchestration’ and want to make a name for themselves. Ask them what SDN, Cloud, Hypervisor, mean and you will get 100 different blah-blah 2 hour speeches. Cisco ACI is really complex I still don’t understand it even after taking a class. Vmware seems to make it simple via their GUI. Tufin’s Ruvi Kitov has had the best perspective to date on how to manage this beast.
So I decided to decode the SDN blah-blah into my own Dreez blah-blah that maybe my mom (The Italian Tornado)

would understand.
In my previous rant on SDN I talked about how this baby will scale massively because scripts can generate 1000’s of objects/rulesets/firewalls in seconds, so the problem is who will manage this beast? CP and Tufin could capitalize on this next big hit.
But first let’s do a primer on SDN and compare were we are today to where we will be in 10 years.
Here is your basic boring enterprise network environment. Let’s start at a a ‘campus’ type environment. A PC is connected to a 3800 Cisco switch in the campus building and that has a leased dedicated 10g fiber to the datacenter 1 or 2 miles away to a Cisco 500 switch. At the campus, there is a firewall with max blades turned on. There are several geographically co-located buildings setup this way in a ‘campus’ network – high speed 10g (expensive) fiber connecting them together. Data is routed between the campus sites and data center (this is key remember this).
Remote sites have MPLS connections. What is MPLS you ask (this is key remember this):
- Buy dedicated guaranteed bandwidth to remote sites
- If you want you could run Layer 2 over these links . So in theory you could get rid of internal L3 routing (this is key) but current limitations on hardware and bandwidth to handle broadcasts restrict this ability.
So remote sites are connected on this dedicated bandwidth MPLS network with speeds of 52K dial-up line to the netherland like Zambia to Ethernet over Fiber 100 Mb at more civilized locales like England. These are connected with Cisco 6X00 routers.
My point of this discussion will be that you can predict the evolution of SDN based on network speeds and prices to remote locations. Just watch…..

Let’s go back in time…waaaay back…to when I had hair. Ethernet was at 1-10Mb 10BaseXXX 1/2 duplex and because of hardware limitations it could only support 10-100 devices all within 500 ft of each other (OK, my numbers might be off but you get the idea). One misbehaving PC sending out too many broadcast messages would bring the network to its knees. Ethernet broadcast storms are like a Wall Street trading floor, 100’s of people all yelling at the same time just slowing the whole thing down and you can’t hear anything. Because of advances in technology today you can have hundreds of devices on 10g Ethernet around the world (if you had enough money) and there is more technology to handle broadcast storms.
With that in mind let’s look at today’s remote sites. Today in Zambia the network link is so slow and unreliable that we have to have some of our servers (file, database, Active Directory) based locally in Zambia or else production would stop. Now what will happen as network speeds increase and become more reliable (Fiber All Around)?

You guessed it, we will then localize those servers back to the data center so they are easier to manage. Many companies already have remote sites with decent low latency bandwidth connectivity so those sites so you will not find any servers, just overpaid whining employees.
So let’s look at the campus infrastructure. This should look like remote sites 2025. They have high bandwidth low latency reliable connectivity to these campus buildings so no need for servers. So by 2025, the only real change will be faster connectivity of both fiber and wireless between my PC and the data center. No big change.

Now the fun part. Let’s look at the data center. Today the data center is filled with OEM equipment. OEM firewalls, database servers, file servers, etc – tied together with via this behemoth Nexus switch(s).Yes we have dramatically started to virtualize this world into VMware and so it is slowly reducing its footprint. As remote network speeds increase and the price of bandwidth decreases and applications migrate back from remote sites to the data center this evolution into the centralized virtual world will hasten linearly?? No I will say exponentially. (stay tuned, its all about the scripts).
Datacenter 2025 will look like this. Either a room filled with 1000’s of $100 gray market PCs running Linux Virtual Systems/VMware OR one big Borg Cube that has 1000’s of CPUs in it tons of memory running VMware or something similar. You can see this now with some of Ciscos products (talk more about this). (I won’t talk about public/private cloud services at this time). Why?

Think of google. Their datacenters are all generic Linux systems. Google and companies are DONE being wedded into the greedy hands of a single vendor. Technology is changing so fast, deployment times are reducing, and prices are dropping so dramatically in the virtual world that being wedded to a OEM is like an Carrie Fisher married to Attila the Hut, just not pretty (She was hilarious in that one Big Bang episode).

(sidenote: If you believe in The Borg, sell your Cisco stock….minimal need for network ports and routing…all done inside The Borg)
So basically, the network infrastructure is headed to fiber and fast wireless all around, 255 TB/sec check it out.

Ok, enough rambling get to the point. L3/routing is currently required because of:
- Router geeks seem to feel that there is some security advantages to subnetting.
- Firewall technology requires us to subnet so we can protect ‘zones’ of IP addresses
- Limit broadcasts to a subnet, if all systems in an enterprise would arp network would stop
- Route across WANs to remote sites (because you can’t arp to find a peer system)
- Networking’s legacy is based on L3. DNS and embedded IP addresses in apps.
- Available network address space. IPv4=2**32 < EUI-64 MAC 2**64 < IPv6 2**128
But sorry to say L3 people, notice how L2 is getting bigger and and L3 is becoming smaller as network bandwidth/speeds/latency improve? Notice how L3 diminishes as you virtualize onto a single Borg Cube? No WAN routing is required in a Borg cube. No IP ‘zones’ required if every virtual guest has a firewall and grouped by virtual host (say tuned more on this later). Fewer arp issues as backplanes get faster and broadcast dampening technology mature inside a virtual host.
Sorry to say L3 people, routing is slowly disappearing. Imagine an enterprise with only L2 worldwide! Imagine being able to fire all your L3 router geeks!
- What will happen to firewall rules? How do we separate networks?
- What will happen to L2 broadcast storms?
- Where does this leave Cisco/Juniper/Alcatel
IP addresses exist because of routing, what happens if we don’t need routing?
Oh yes, I can see all you Cisco and Security geeks roll your eyes. How can your comfy little world disappear from under your feet when you have mortgages to pay and boat loans to pay off?
[music stops]
But we still have mainframes
[music continues]
Well, you can relax IP addresses will be around for a long time just like COBOL is still out there….but you might want to think about sprucing up your resume.
In 2025, a CIO will wake up and decide he/she wants to spin up a 1000 server big data mining site to find aberrations in health care pricing. You get the phone, what do you do? Do you call India and start hiring deployment geeks for $2/hour? NO! You write a Python/PHP/Perl script.
for server= 1 to 1000 DO{
server_farm[server] = windowsserver.create_new; # create new server
assign_networking( server_farm[server] ); # assign networking template to server
assign_security_controls(server_farm[server] ); # assign security template to server
assign_application(application_ptr, server_farm[server]); # load application on server
start_server( server_farm[server] ); # start the server
}
Deployments will be like writing software…generate and destroy objects and constructs at line speeds. On you management station you group these 1000 servers into a group, create a firewall and build a policy that says:
# Allow users to connect
FROM: user_pc TO: server_farm ACTION: ACCEPT
# Nothing leaves the server farm
FROM: server_farm TO: NOT server_farm ACTION: DENIED
Do you see any IP addresses? Do you see teams of overpaid IT people running around plugging in cables and entering Cisco commands?
Welcome to 2025 Software Defined Networking……..




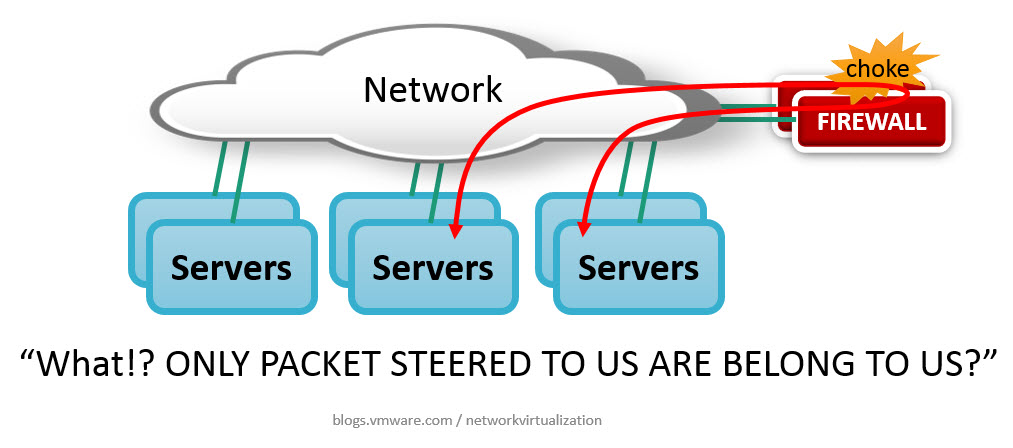







 T
T








